-
머신러닝 가이드-지도학습파이썬 머신러닝 2023. 7. 2. 15:56
인터넷을 찾아보면서 기능 하나하나를 소개하는 자료는 많지만 실제 데이터를 전처리하여, 이에 알맞는 학습 모델을 선택하고, 모델을 평가하는 전반적인 과정을 소개하는 자료는 부족한 것 같았다. 그래서 친숙한 BMI를 통해 지도학습이 어떻게 진행되는 지 소개하기로 하였다.
0.코딩 환경 구축
https://sidreco.tistory.com/14
파이썬 + VScode 머신러링 환경 구축
아나콘다 + jupyter notebook이나 google colab 등이 있지만, 아나콘다는 쓸대없이 무겁고, colab은 데이터 파일 올리기가 귀찮다. 필자는 직접 파이썬을 설치하여 pip로 필요한 패키지만 설치하는 것을 선
sidreco.tistory.com
pandas(전처리), scikit-learn(학습), matplotLib(시각화)가 필요하니 설치되있지 않다면 pip를 통해 설치를 하면 된다.
1.데이터 준비
연습용 데이터는 sklearn.dataset에 내장되어 있는 것을 사용하여도 되지만, 공공데이터 포털 등에서도 얻을 수 있다.
공공데이터 포털
국가에서 보유하고 있는 다양한 데이터를『공공데이터의 제공 및 이용 활성화에 관한 법률(제11956호)』에 따라 개방하여 국민들이 보다 쉽고 용이하게 공유•활용할 수 있도록 공공데이터(Datase
www.data.go.kr

BMI를 구하는데 키와 몸무게가 필요하므로 국민건강보험공단_건강검진정보를 검색한다.

여기서 csv 형태에 데이터를 다운받아 원하는 폴더로 옮겨준다.

그리고 이 폴더를 VScode로 열어준다.



이후 ipynb 파일을 만든다.
2.데이터 전처리
엑셀을 이용해 csv 파일을 수정하여 전처리할 수 도 있지만, 파이썬의 pandas를 이용하여 설명한다. 전처리에서 할 작업은 키와 몸무게만 골라낸 뒤, 결측값을 처리, BMI와 저체중~비만을 나타내는 체중 상태 열을 추가, 학습 데이터와 검증 데이터 나누기 이다. 학습 모델에 따라 표준화가 필요할 수 도 있다.
필요한 모듈 import
import numpy as np import pandas as pd from sklearn.model_selection import train_test_split #훈련 데이터와 테스트 데이터로 나누는 함수 from sklearn.preprocessing import StandardScaler #데이터를 표준화해주는 클래스데이터 불러오기
df = pd.read_csv("국민건강보험공단500.csv", encoding="euc-kr") df.info() df

데이터가 많으면 불러오고 처리하는데 오래걸리니 적당히 500개로 잘랐다. (데이터는 다운받은 자료가 아닌 예전에 실습할 때 사용하였던 데이터이다.) 여기서 NaN는 결측값으로 데이터가 입력되지 않을 것이다. 분석할 때 결측으로 남아있으면 안되니 결측값을 .dropna() 매서드를 사용하여 버릴 수 있으며, .fillna() 매서드로 0이나 평균값으로 매워서 처리할 수 있다.
필요한 데이터 선택
BMI를 구하는데 키와 몸무게만 있으면 되는데 명확하니, 이들만 추출하여 사용하면 되지만, 실제 데이터를 처리할 때는 사람이 관련이 있을 것 같은 데이터를 선택하게 된다.
#데이터 선택 data = df[["신장(5Cm단위)", "체중(5Kg 단위)"]] data.columns = ["신장(cm)", "체중(kg)"] #특정 열이름만 바꾸고 싶다면 .rename(columns={"신장(5Cm단위)":"신장(cm)"}) data*단위를 Cm, Kg으로 적은 것이 마음에 들지 않아 이름을 바꾸었다. 그리고 Cm단위 kg 단위 이렇게 띄었다 안띄었다 불규칙하면, 밑에서 코딩하다가 띄어쓰기 틀려서 오류나기 쉬운 것은 덤이다. (VScode를 사용하면 intelisense가 자동완성 해주는데 jupyter는 그런거 없다.)

데이터 추가
#BMI 열 추가 data["BMI"] = data["체중(kg)"]/(data["신장(cm)"]/100)**2 data
#체중상태 열 추가 #BMI가 18.5 이하면 저체중 / 18.5 ~ 22.9 사이면 정상 / 23.0 ~ 24.9 사이면 과체중 / 25.0 이상부터는 비만으로 판정 data["체중상태"] = ["저체중" if x < 18.5 else "정상" if x < 23.0 else "과체중" if x < 25.0 else "비만" for x in data["BMI"] ] data
여기서는 파이썬의 List Comprehension과 삼항 연산자가 쓰였다.
List Comprehension은 for 문을 리스트 안으로 집어넣어서 한줄로 간략하게 쓸 수 있게 해주는 문법이다.
#List Comprehension [(표현식) for (변수) in (리스트)] [(표현식) for (변수) in (리스트) if (조건)] [(표현식) for (변수) in (리스트) if (조건) else (조건이 성립하지 않을 때)] [(표현식) for (변수1) in (리스트1) for (변수2) in (리스트2)] #뒤에 for 부터 실행 #삼항 연산자 (참일때) if (조건식) else (거짓일 때) #중첩 사용 [(삼항 연산자 중첩 .. if .. else .. if .. else ..) for (변수) in (리스트)]모집단 정보 보기
#모집단 정보 numfat = [len(data.where(data["체중상태"] == "저체중").dropna()), len(data.where(data["체중상태"] == "정상").dropna()), len(data.where(data["체중상태"] == "과체중").dropna()), len(data.where(data["체중상태"] == "비만").dropna()) ] fatinfo = pd.DataFrame({"명": numfat}, index=["저체중", "정상", "과체중", "비만"]) fatinfo["백분률"] = fatinfo["명"]/np.sum(fatinfo["명"])*100 fatinfo
데이터 프레임의 메서드인 where로 해당 조건을 만족하는 행만 남기도 나머지는 모두 NaN 값으로 날린 뒤 dropna()로 NaN이 있는 행을 모두 버렸다. 이후 데이터의 행수를 세면 저체중 몇 명인지 정상 몇 명인지 나오게 된다.
3.지도학습-분류 (로지스틱 회귀)
회귀라고 이름이 붙었지만 분류 알고리즘이다. 로지스틱 곡선은 실수 전체가 정의역이며 치역은 0~1사이인데다 시그모이드 개형으로 누적확률 분포함수의 성격을 띈다. 예를 들어 x축을 담배피운 기간을 표준화한 값, y축을 폐암일 확률이라 생각을 하자 단순하게 담배를 핀 기간에 비례하여 폐암환자일 확률이 올라간다고 할 때 확률 분포 함수는 아래와 같은 시그모이드 개형을 가질 것이다.
$$f(x)=\frac{1}{1+e^{-x}}$$

*그래프를 보면 왜 표준화가 필요한 지 알 수 있다. 그래프를 평행이동시키는 것보다 표준화하는 것이 훨씬 간단함
로지스틱 회귀 함수값을 반올림하여 이다 아니다가 판별이 난다.(0.5일 경우 구현체 마다 판단이 다르나 scikit-learn에서는 음성으로 판별한다.)
다변수인 경우 아래와 같이 다중 회귀와 결합하여 입력값이 조절된다.
$$y=f(w_0 + w_1 x_1 + w_2 x_2 + \cdots + w_n x_n )$$
여기서 \(w_0\)라는 절편과 \(w_n\)라는 가중치는 로지스틱 비용함수를 통해 구한다.
다중 분류인 경우에는 로지스틱 곡선을 여러개 만드는 것으로 해결하는데, k개로 분류한다면 k-1개의 로지스틱 곡선이 만들어 진다. 마지막 k번째 클래스에 속할 확률은 1-(아닐 확률)로 정해지기 때문이다.
그럼 키와 몸무게 데이터를 이용하여 체중 상태를 분류하여 보자
로지스틱 회귀를 위한 전처리
feacture = data[["신장(cm)", "체중(kg)"]].to_numpy() #feacture 만 따로 분리 label = data["체중상태"].to_numpy() #훈련 데이터와 테스트 데이터로 나누기 state_train_feacture, state_test_feacture, state_train_label, state_test_label = train_test_split(feacture, label, test_size=0.3) #실수형 데이터의 표준화 ss = StandardScaler() ss.fit(state_train_feacture) #표준화에 사용될 실수형 데이터의 평균과 표준편차 계산 state_train_scaled = ss.transform(state_train_feacture) state_test_scaled = ss.transform(state_test_feacture)지도학습에서 입력할 데이터는 feacture이고, 해당 feacture에 대한 정답은 label이라 한다. 그리고 분류 종류는 class라 한다.
모델 학습
#모델학습 from sklearn.linear_model import LogisticRegression logi_model = LogisticRegression(max_iter=1000) #max_iter = max iteration logi_model.fit(state_train_feacture, state_train_label) #학습/테스트 데이터 정확도 출력(0~1) print("학습셋:", logi_model.score(state_train_feacture, state_train_label)) print("테스트셋:", logi_model.score(state_test_feacture, state_test_label))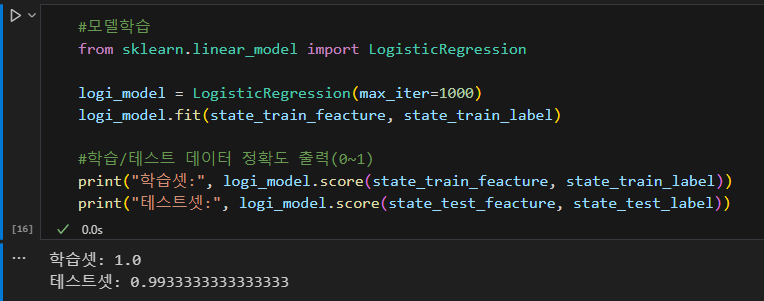
*훈련 데이터와 테스트 데이터는 랜덤하게 나누어지므로 껏다가 다시 실행하면 정확도가 다르게 나올 수 있다.
여기서는 한개만 하였지만 여러 모델을 시도해보고 정확도가 가장 높은 것을 선택하게 된다. 그리고 이진분류인경우 피벗테이블을 통해 모델을 평가하게 된다.
번외) 계수와 절편 확인해보기
#로지스틱 비용함수로 구한 다항 회귀식의 계수(가중치) 절편 확인 print("신장, 체중") for i in range(0,4): print(logi_model.coef_[i], logi_model.intercept_[i]) #coef는 coefficient, intercept는 절편
각 클래스 별로 회귀를 진행한 것을 알 수 있다.
확인해보기(상단 4개 데이터만)
#클래스별 예측 확률 (상단 4개 데이터) print(logi_model.classes_) #입력순이 아니라 가나다 순으로 정렬됨 for i in range(0,4): print(logi_model.predict_proba([state_test_feacture[i]]), logi_model.predict([state_test_feacture[i]]))
파라미터가 2차원을 요구해서 한 번 리스트를 씌워주어야 한다. 가장 높은 확률의 클래스를 택하는 것을 알 수 있다.
4.지도학습-회귀 (SVR)

https://ko.wikipedia.org/wiki/%EC%84%9C%ED%8F%AC%ED%8A%B8_%EB%B2%A1%ED%84%B0_%EB%A8%B8%EC%8B%A0 Support Vector Regression, SVR은 분류에 많이 쓰이는 Support Vector Machine을 회귀에 적용한 것이다.
각각의 feacture를 기저벡터의 성분으로 하여 만든 고차원 공간에서 초평면과 가장 가까운 점사이 거리(Margin)가 최대가 되는 초평면을 찾으면 이 초평면을 기준으로 클래스를 분류할 수 있을 것이다. 회귀에서는 거꾸로 ε(허용 오차, Margin의 폭)을 두고 Margin 안에 최대한 데이터가 많이 들어가게 하는 초평면을 구한다.

https://ko.wikipedia.org/wiki/%EC%84%9C%ED%8F%AC%ED%8A%B8_%EB%B2%A1%ED%84%B0_%EB%A8%B8%EC%8B%A0 이와 같은 방식은 데이터가 선형인 경우에는 잘 작동하지만 비선형인 경우 제대로 예측하지 못하는데, 커널 함수를 사용하여 초평면을 구하게 되면, 비선형 곡선을 구할 수 있게 된다. 지수 함수 같은 경향을 따르는 데이터에 로그를 취하게 되면 데이터가 선형으로 나타나듯이, 커널 함수를 통해 데이터가 최대한 선형이 되도록 변환하여 초평면을 구하고 이를 역변환하여 다시 돌리는 것이다.
SVM 데이터 전처리
feacture = data[["신장(cm)", "체중(kg)"]].to_numpy() #feacture 만 따로 분리 label = data["BMI"].to_numpy() #훈련 데이터와 테스트 데이터로 나누기 bmi_train_feacture, bmi_test_feacture, bmi_train_label, bmi_test_label = train_test_split(feacture, label, test_size=0.3)학습 및 커널 비교
#SVR 모델 커널 비교 from sklearn.svm import SVR kernel_list = ["rbf", "poly", "sigmoid"] for kernel in kernel_list: #C(constrain)는 규제강도, 높을수록 학습 데이터에 강하게 fit 함, 너무 높으면 과대적합 문제 발생 가능 (기본값 1) #epsilon은 허용 오차, 예측값과 실제값 사이 허용 거리를 의미 SVR_model = SVR(C=10, epsilon= 0.2, kernel=kernel) SVR_model.fit(bmi_train_feacture, bmi_train_label) print("====================================") print("커널:", kernel) print("결정계수 R^2:", SVR_model.score(bmi_test_feacture, bmi_test_label)) #모델간의 성능을 비교하는데 결정계수가 좋음 print("RMSE:", np.sqrt(np.mean((SVR_model.predict(bmi_train_feacture)-bmi_train_label)**2)) )
*linear 등의 다른 커널도 있다.(linear는 그냥 초평면을 찾는 것)
결정 계수가 가장 높은데가 RMSE(Root Mean Square Error)가 가장 작은 rbf 커널을 선택하면 된다.
이경우에는 해당사항이 없으나 RMSE는 데이터의 숫자와 범위 등에 영향을 받으므로 데이터 셋이 다른 경우 두 모델을 비교하기 어렵다. 즉 데이터를 표준화하여 입력한 모델과 그렇지 않은 모델을 비교하는 데 RMSE를 사용하는 것은 적합하지 않다. 이러한 경우 사용할 수 있는 것이 결정 계수 \(R^2\)(Coefficient of Determination, R-square)이다.
$$R^2=\frac{ESS}{TSS}$$
$$ESS=\sum_{i=1}^{n} (\hat{y_i} - \bar{y})^2$$
$$TSS=\sum_{i=1}^{n} (y_i - \bar{y})^2$$
*여기서 \(\hat{y_i}\)는 회귀로 추정한 값이다.
\(TSS\) 는 Total Sum of Squares 편차 제곱합(SST라고도 함), \(ESS\)는 Explained Sum of Squares로 Sum of Squares due to Regression (SSR)이라고도 한다. 이것의 의미는 전체 데이터 중 설명이 가능한 데이터의 비율로 1에 가까울수록 해당 종속 변수를 설명하는 데 필요한 feacture가 많이 포함되어 있다는 뜻이므로 좋다. 그러나 별로 상관관계는 없으나 우연히 맞을수도 있고, 과적합 문제도 있으니 맹신할 수는 없다. 그리고 sigmoid 처럼 모델이 완전히 들어 맞지 않다면 \(R^2\)이 음수로 나오게 된다.
선택한 모델 학습 및 결과 확인
#모델 학습 SVR_model = SVR(C=10, epsilon= 0.2, kernel="rbf") SVR_model.fit(bmi_train_feacture, bmi_train_label) #보여주기 display_chart = pd.DataFrame(bmi_test_feacture) display_chart.columns = ["신장(cm)", "체중(kg)"] display_chart["BMI"] = data["BMI"] display_chart["predicted BMI"] = SVR_model.predict(bmi_test_feacture) display_chart
350개 데이터로는 BMI 추정하기가 부족해보인다.
데이터 시각화
회귀 같은 경우 데이터를 확인하는 데 표보다 그래프로 나타내는 것이 나을 수 있다.
#3D 그래프로 결과 확인해보기 import matplotlib.pyplot as plt #한글 폰트 설정 from matplotlib import font_manager, rc font = font_manager.FontProperties(fname="C:/Windows/Fonts/NGULIM.TTF").get_name() rc("font", family=font) fig = plt.figure(figsize=(9,6)) ax = fig.add_subplot(111, projection="3d") ax.scatter(display_chart["신장(cm)"], display_chart["체중(kg)"], display_chart["BMI"]) ax.scatter(display_chart["신장(cm)"], display_chart["체중(kg)"], display_chart["predicted BMI"]) plt.title("BMI") ax.set_xlabel("신장(cm)") ax.set_ylabel("체중(kg)")
데이터가 밀집되어있는 부분에서는 그럭저럭 비슷하게 나오지만, 끝부분에서는 많이 어긋나있는 것을 확인할 수 있다.
6.모델 저장하고 불러오기
#모델 파일로 저장하기 import joblib joblib.dump(SVR_model, "bmi-learn.pkl")#모델 불러오기 loaded_model = joblib.load("bmi-learn.pkl") print("R^2:", loaded_model.score(bmi_test_feacture, bmi_test_label))pkl은 파이썬 전용이며, json으로 저장하면 다른 언어에서도 모델을 불러와 사용할 수 있다.
대표적인 지도학습 알고리즘
분류 로지스틱 회귀, SVM, KNN, 의사결정트리 등 회귀 선형 회귀, 다항 회귀, 다중 회귀, SVR 등 로지스틱 회귀
https://aws.amazon.com/ko/what-is/logistic-regression/
로지스틱 회귀란 무엇인가요? - 로지스틱 회귀 모델 설명- AWS
로지스틱 회귀는 인공 지능 및 기계 학습(AI/ML) 분야에서 중요한 기법입니다. ML 모델은 학습을 통해 사람의 개입 없이 복잡한 데이터 처리 작업을 수행할 수 있는 소프트웨어 프로그램입니다. 로
aws.amazon.com
[혼공머] Logistic Regression(로지스틱 회귀)
공부 벌레🐛 되려다 머리가 터지려는 요즘...🤯📚 교재: 혼자 공부하는 머신러닝+딥러닝🔗 로지스틱 회귀🔗 로지스틱 회귀분석의 원리와 장점🔗 위키백과 - 로지스틱 회귀저는 위 교재 흐름
velog.io
SVR
https://wooono.tistory.com/111
[ML] SVM (Support Vector Machine) 이란?
Support Vector Machine 이란? 분류(classification), 회귀(regression), 특이점 판별(outliers detection) 에 쓰이는 지도 학습 머신 러닝 방법 중 하나이다. SVM 의 종류 scikit-learn 에서는 다양한 SVM 을 지원한다. SVC Cla
wooono.tistory.com
'파이썬 머신러닝' 카테고리의 다른 글
[재업]차원 축소와 주성분분석(Principal Component Anaylse, PCA) (1) 2024.02.09 [Matplotlib]파이썬 기본 데이터 시각화 (1) 2023.12.24 파이썬 + VScode 머신러링 환경 구축 (0) 2023.07.02